

目录
前言
说明:这个 Session 的链接已打不开,不知为何下掉了,但在 wwdc.io 的 macOS 应用中可以查看。
WWDC16 - Session406: <Optimizing App Startup Time> 介绍了基于 dyld 2 的系统内,进程是如何启动的,在 main() 之前做了哪些事情,并结合理论和实践给出了优化启动时间的方法。
1. 谁想看这个 Session
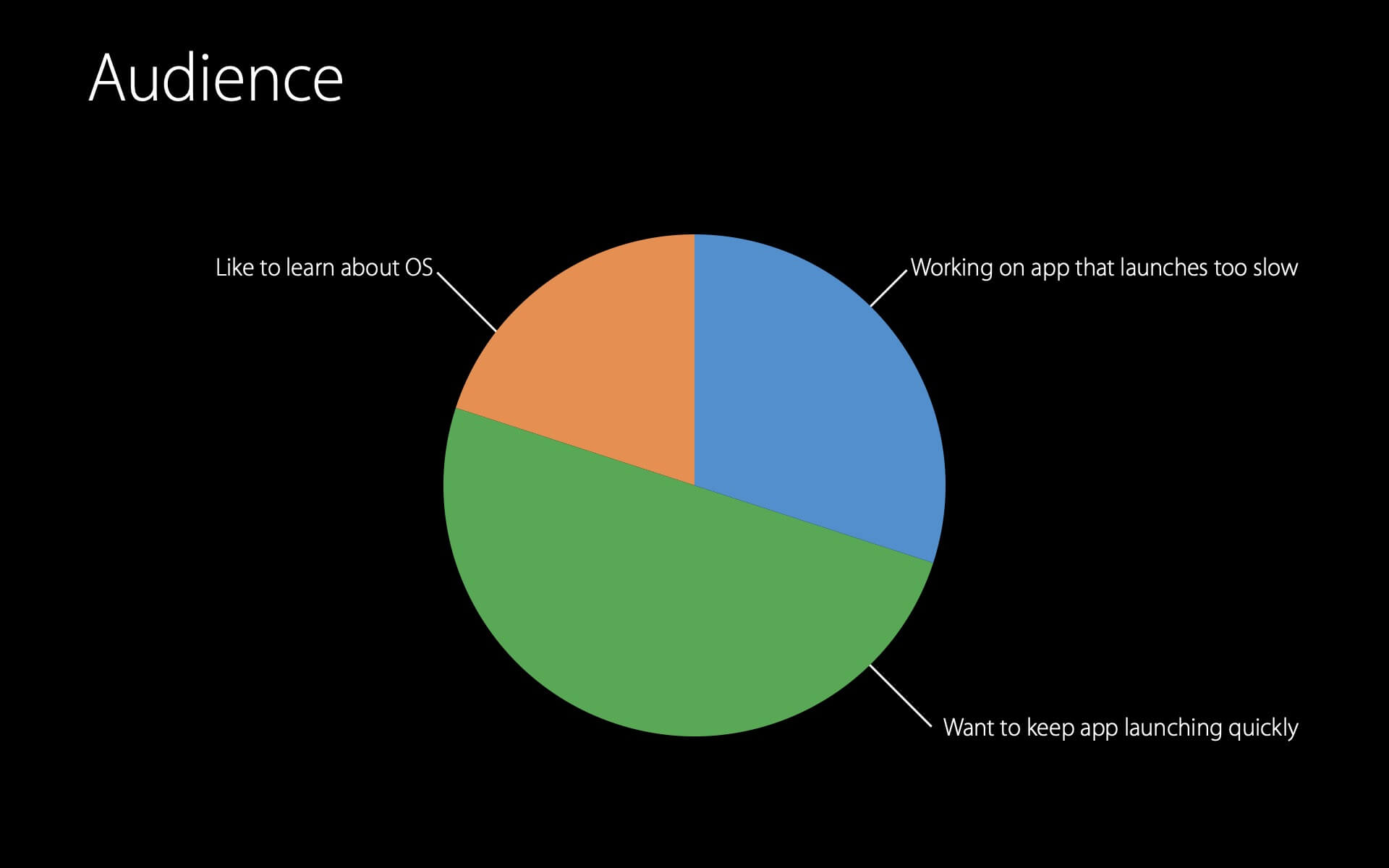
Apple 的市场团队做了一些调查,结果显示这 3 个群体将在此 session 中有所收获:
- 当前开发的 App 启动太慢
- 不想成为前一类人(想让 App 保持快速启动)
- 想了解系统的运作方式
2. 内容提要
- 理论
Mach-O格式- 虚拟内存 (Virtual Memory)的基础
Mach-O二进制文件的加载- 从系统调用
exec()到应用的main()函数之间发生的所有事情
- 实践
- 测量
main()函数之前消耗的时间 - 优化启动时间
- 测量
Mach-O 简介
术语

Mach-O 是 Mach Object 文件格式的缩写,它包含一系列文件类型:
- Executable: App 或 App Extension 中主要的二进制文件
- Dylib: 动态库(aka
DSO或DLL) - Bundle: 无法被链接的特殊的 dylib ,只能用
dlopen()打开,比如 macOS 上使用的 plug-ins 。
Image: executable 或 dylib 或 bundle 。
Framework: 包含目录的 dylib,目录中有 dylib 需要的资源文件和头文件。
Segment

Mach-O 文件由多个 segment 组成,其名称由下划线和大写字母构成,如:__TEXT,__DATA,__LINKEDIT。
每个 segment 都是页大小 (page size) 的整数倍,页大小在不同的设备上不一样:
- 在 arm64 上是 16KB
- 在其他架构上是 4KB
在上图示例中,__TEXT 包含 3 个页,__DATA 和 __LINKEDIT 各包含一个页。
Section
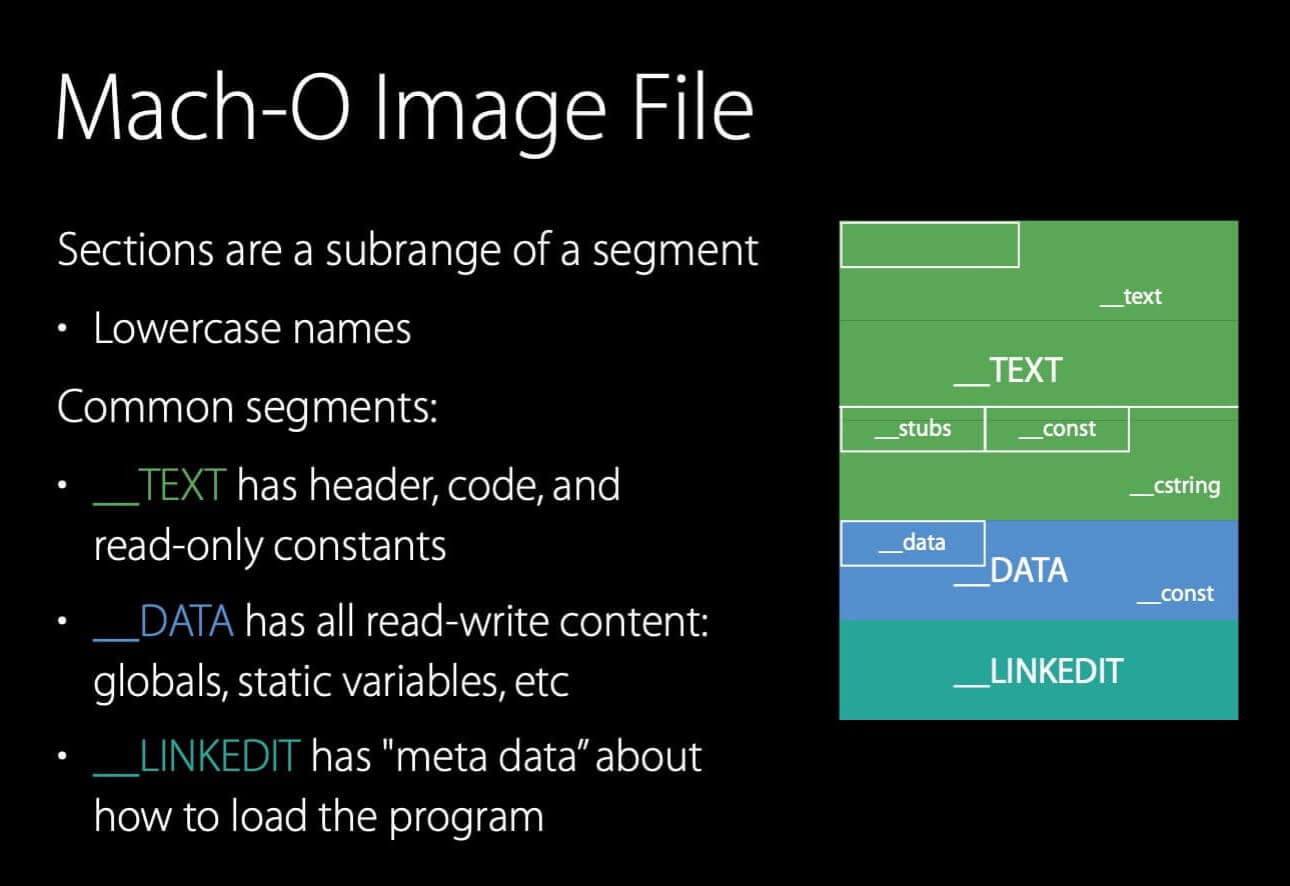
section 是编译器忽略的东西,它们只是 segment 的子区域。它们的大小没有被限制为页大小的整数倍,但它们是不重叠的 (non-overlapping) 。
其名称由下划线和小写字母构成,如:__text,__stubs ,__const 等。
Segment 的类型
通用的 segment 有这些:
__TEXT:位于文件的开头处,包含Mach-O header、代码、只读的常量;__DATA:包含所有的可读可写的内容,如:全局变量、静态变量等;__LINKEDIT:包含关于如何加载这个程序的“元数据”,如:代码签名、符号表等。
Mach-O Univeral Files

- 假设我们在构建一个 64 位的 iOS 应用 ,Xcode 会为我们生成一个 arm64 架构的 Mach-O 文件;
- 如果改为也支持 32 位的设备,当我们在 Xcode 内 rebuild 的时候,会生成一个新的 armv7s 架构的 Mach-O 文件。
这两个文件最终会合并为一个新的文件,这个文件就是 通用 Mach-O 文件 (Mach-O Univeral Files) ,或称作通用二进制文件、胖二进制文件。

由此可知,Mach-O Univeral Files 是包含多个架构的二进制文件,它的起始处有一个 Fat Header,里面有个列表记录了所有的架构以及它们在文件中的偏移量。这个 Fat Header 的大小是一个页。
虚拟内存简介

你也许会感到疑惑:
- 为什么 segment 的大小需要是页大小的整数倍?
- 为什么
Mach-O Header是一个页的大小,这浪费了很多空间。
它们基于页的原因,与虚拟内存有关。
间接层
The adage in software engineering that every problem can be solved by adding a level of indirection
软件工程中有句名言:每个问题都可以通过增加间接层 (indirection) 来解决。
虚拟内存 (Virtual Memory, VM)解决的问题是,当系统中有很多进程 (process) 时,如何管理机器的物理内存 (physical RAM) 。
系统设计者的做法就是添加了一个间接层:每个进程都是一个逻辑地址空间 (logical address space) ,它们会被映射到一些物理内存页 (physical page of RAM) 。
这个映射不一定是一对一的:
- 某个进程中的一些逻辑地址可能没有映射到物理内存 ;
- 多个进程的逻辑地址可能会映射到相同的物理内存 。
这种设计提供了很多机会。下面介绍虚拟内存一些的特性。
1. 缺页中断
如果某进程内的一个逻辑地址没有映射到物理内存 ,当这个进程访问该逻辑地址时,就会发生一次 缺页中断 (page fault) 。此时,内核将停止这个进程,并试图找出需要发生什么。
2. 多个进程共享物理内存
两个进程的不同的逻辑地址可能会映射到相同的物理页,也就是说这两个进程可共享相同的物理内存。
3. File backed mapping
…(这里需要更详细的解释)
可以通过 mmap 调用告诉 VM 系统,将文件的部分内容映射到进程中的某个地址范围,而不是将整个文件读入。当 page fault 发生的时候,只读取缺失的那一个页,也就是对文件执行惰性加载。
因此,Mach-O 的 __TEXT 段可以被映射到多个进程,可以被惰性读取,可以在多个进程之间共享。
4. 写时复制 (copy on write)
对于 __DATA 段,由于它是可读可写的,因此会对它使用写时复制技术,这与 Apple file system 上拷贝文件的操作类似。
其机制是,当多个进程只是读取全局变量时,会在多个进程之间地共享 __DATA 页;当某个进程尝试往 __DATA 页写入内容时,就会触发写时复制 。
写时复制导致内核将该页复制到另一段物理内存 中,并将映射重定向到该物理内存中。所以这个进程就有了它自己的那个页的副本。
5. Dirty page & Clean page
上面提到的通过 copy 得到的 page 就是 dirty page 。
- Dirty page:包含特定进程信息的页。
- Clean page:不包含特定进程信息的页。如果需要,内核可以重新生成 clean page ,比如重新从磁盘读取。
由此可知,dirty page 比 clean page 昂贵得多。
6. 页的权限
可以对 Mach-O 文件的每个页设置访问权限。权限可以是 r 、w 、x 的任意组合。
Mach-O 文件加载到虚拟内存
前面分别介绍了 Mach-O 和虚拟内存,接下来我们用一个例子来看看它俩是如何协作的。
在接下来的示例中,将介绍两个进程加载同一个 dylib 的详细流程(假设这个 dylib 之前还没有被加载过)。
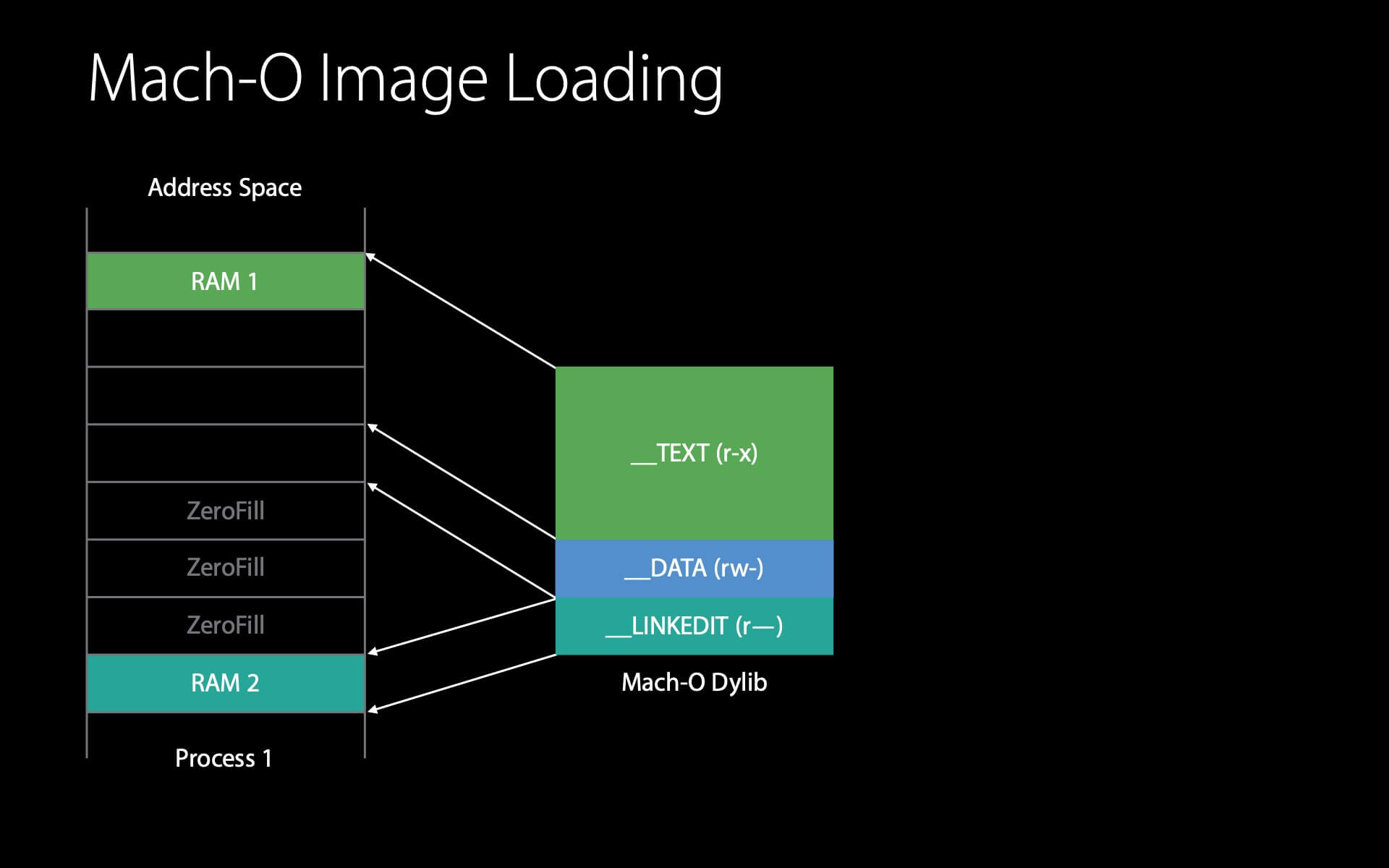
示例:第一个进程加载 dylib
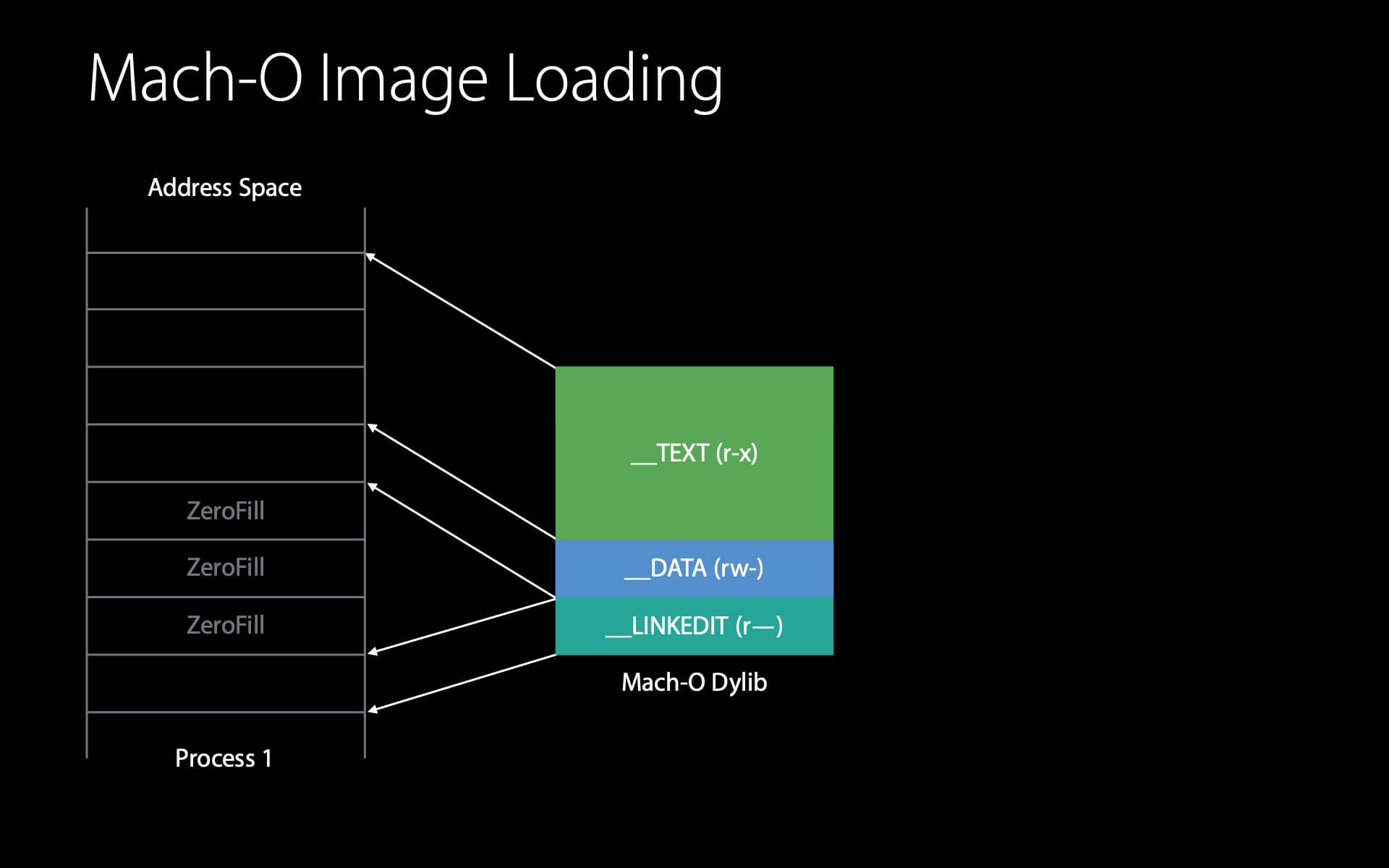
如图所示,这里有一个 dylib 文件,我们不是在内存中读取它而是在内存中映射它 (rather than reading it in memory we’ve mapped it in memory) 。在内存中,这个 dylib 需要 8 页。
这里的节省的不同之处在于这些填充的 0 (ZeroFills) 。大部分全局变量的初始值是 0 ,因此,静态链接器进行了优化,将所有值为零的全局变量移到末尾,这样就不会占用磁盘空间。在虚拟内存中,当这个页第一次被访问时会用 0 填充,因此不需要读取。
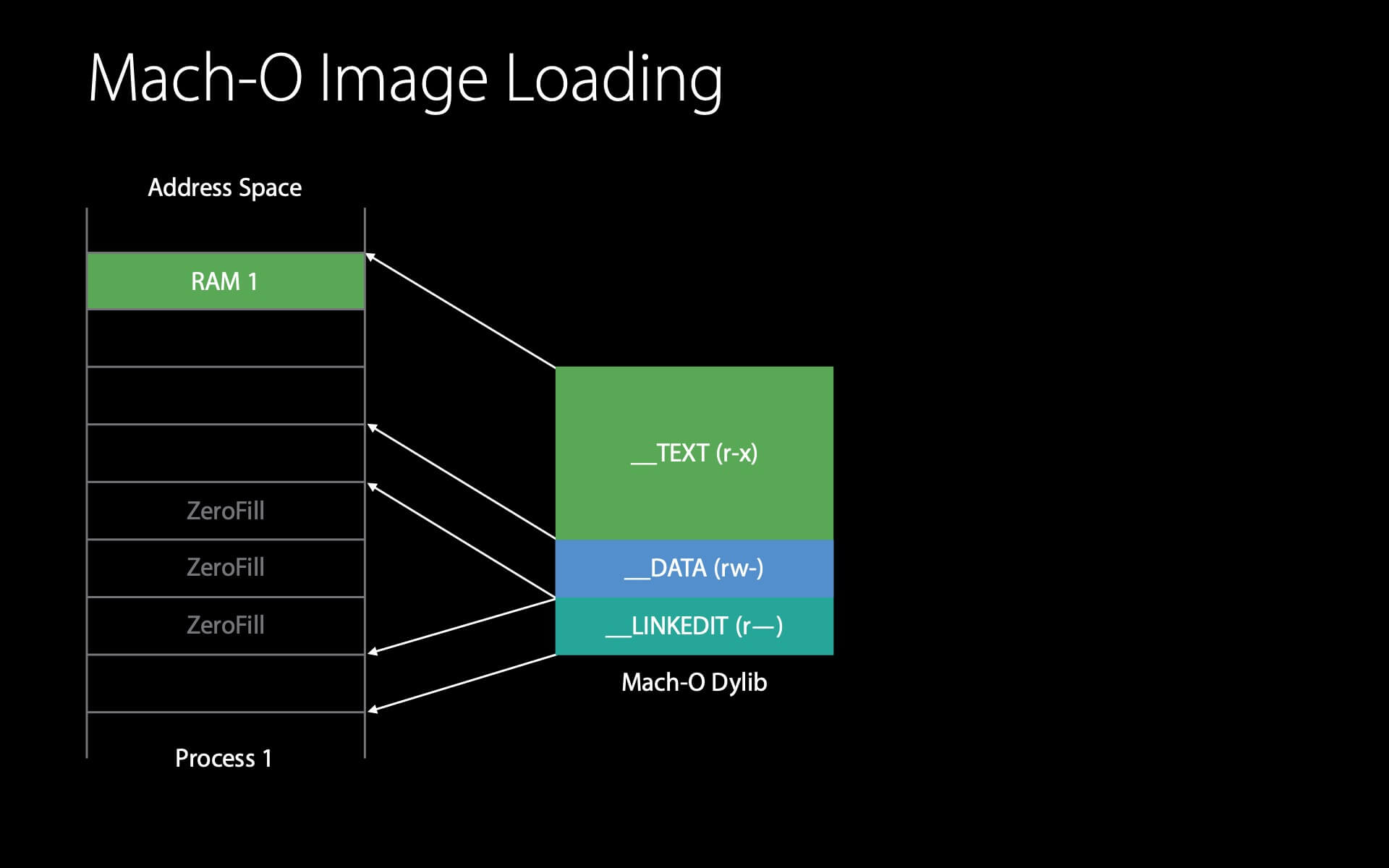
dyld 要做的第一件事是在进程中、物理内存中查看 Mach-O header,此时 Mach-O header 还没有加载到物理内存中,因此会发生一次 page fault 。然后,内核将读取 Mach-O 文件的第一页并置于物理内存中,再设置好虚拟内存到物理内存的映射。
现在,dyld 就可以开始读取 Mach-O header 了。Mach-O header 会告知 dyld 需要去 __LINKEDIT 页中读取一些信息,此时,会再发生一次 page fault 。同样,内核会将 __LINKEDIT 读入物理内存并设置好映射。
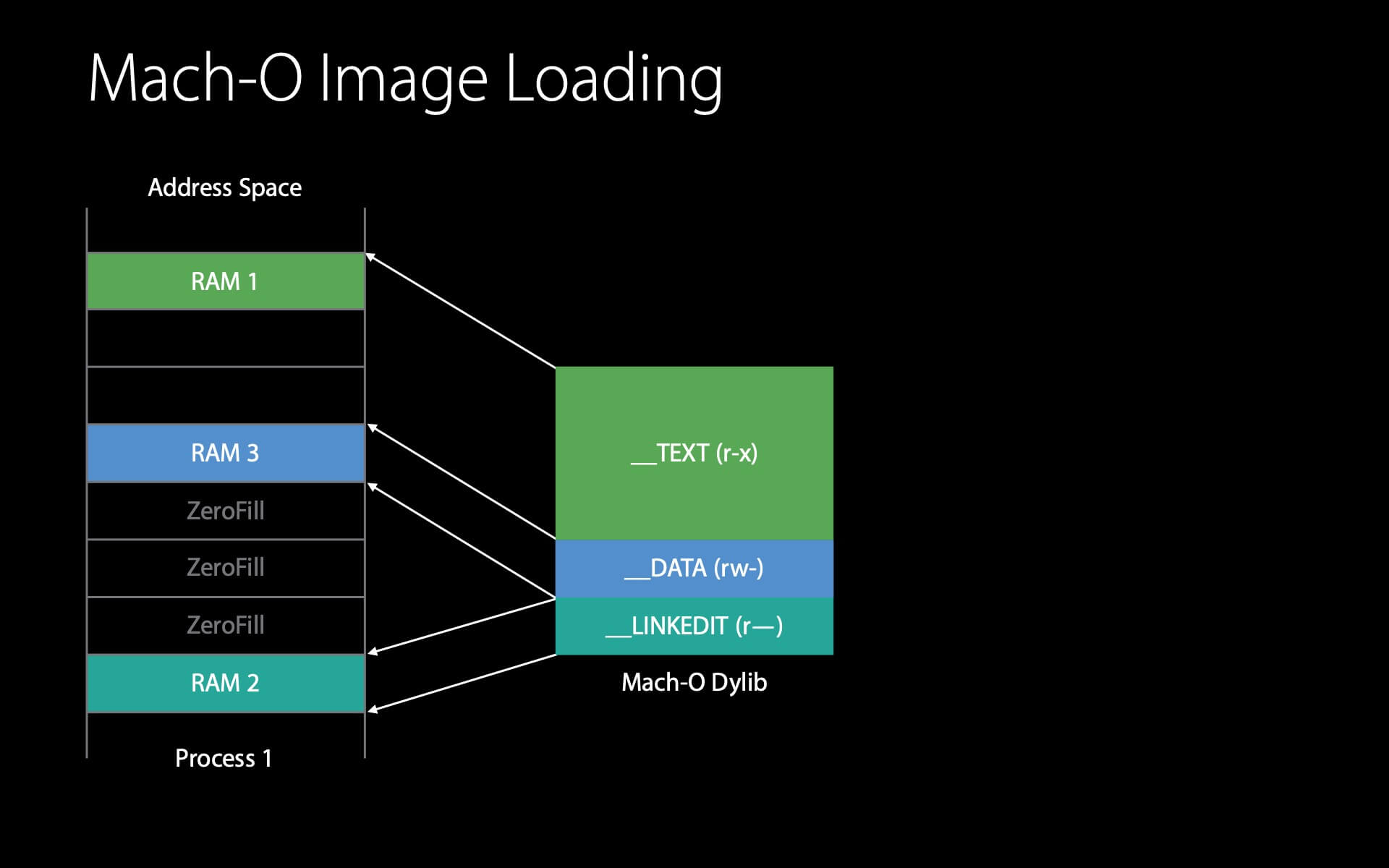
接着,这个 __LINKEDIT 页会告诉 dyld 需要对 __DATA 页做一些 Fix-ups ,以使这个 dylib 可运行。读取这个 __DATA 页的流程与之前类似。
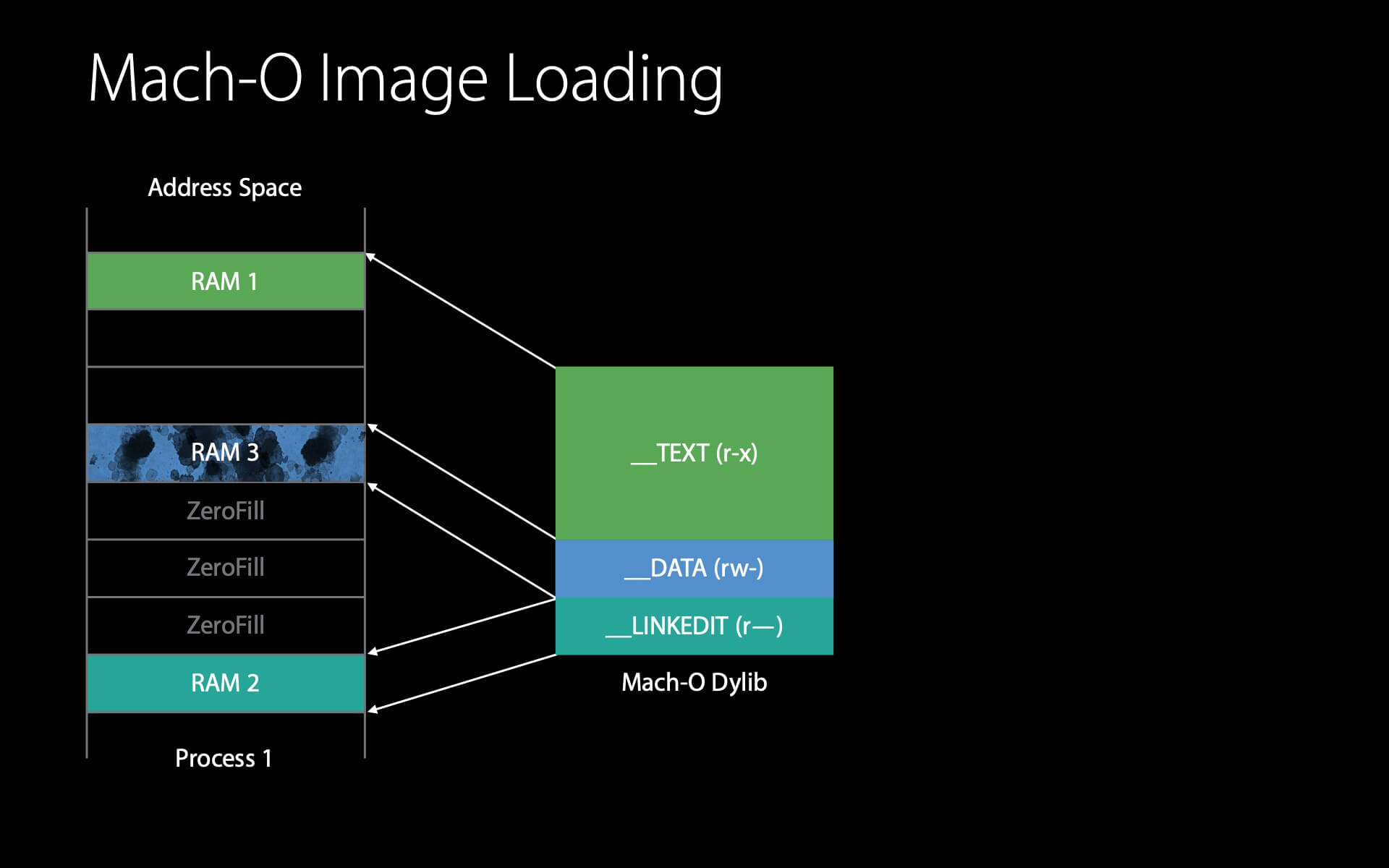
与前面不同的是,dyld 在做 Fix-ups 时,会往这个 __DATA 页写入内容,此时就触发了写时复制,就产生了一个 dirty page 。
第一个进程加载 dylib 的小结:
- 如果我们只是简单地分配 8 页空间,然后把整个 dylib 读入,会产生 8 个 dirty page ;
- 我们按上述模式按页加载,只会产生 1 个 dirty page 和 2 个 clean page 。(小编注:演讲者应该是漏掉了
__DATA的 clean page ,所以应该是 3 个 clean page )
示例:第二个进程加载 dylib
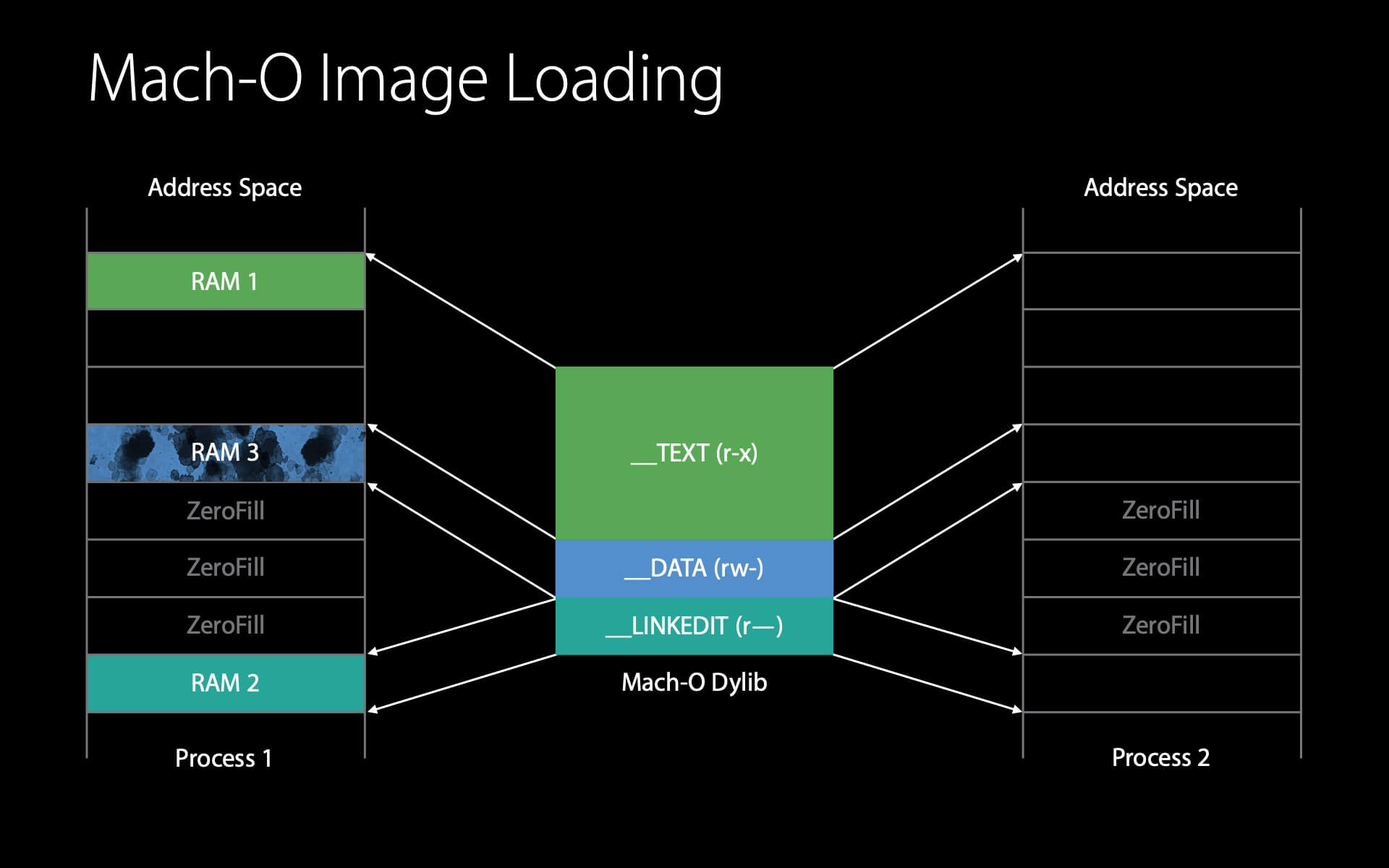
当第二个进程也加载这个 dylib 时,流程是相似的。
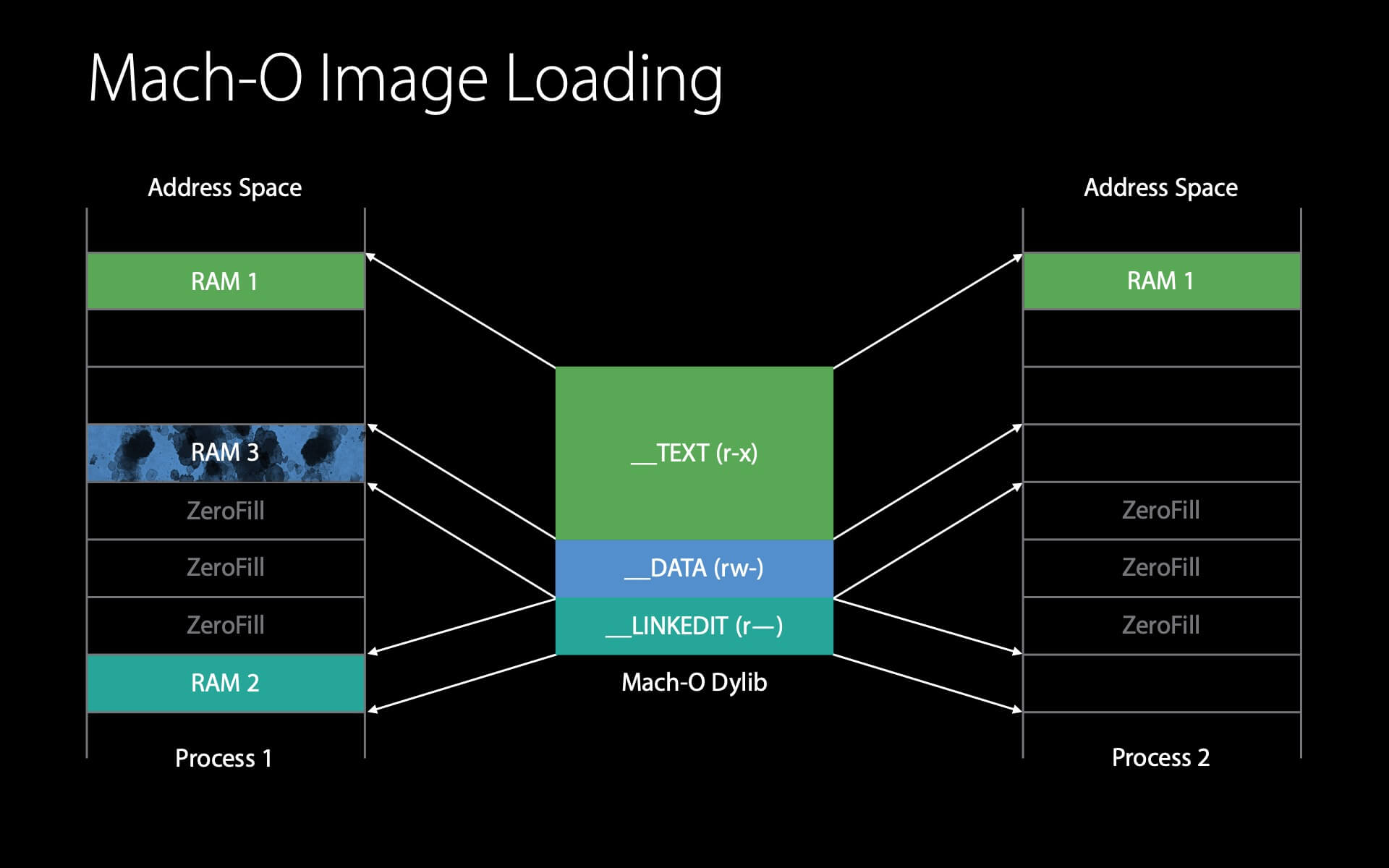
首先 dyld 查看 dylib 的 Mach-O header,这时内核发现它已经在物理内存中了,因此只需要简单地设置映射就能复用这个页了,这个过程没有 IO 操作。
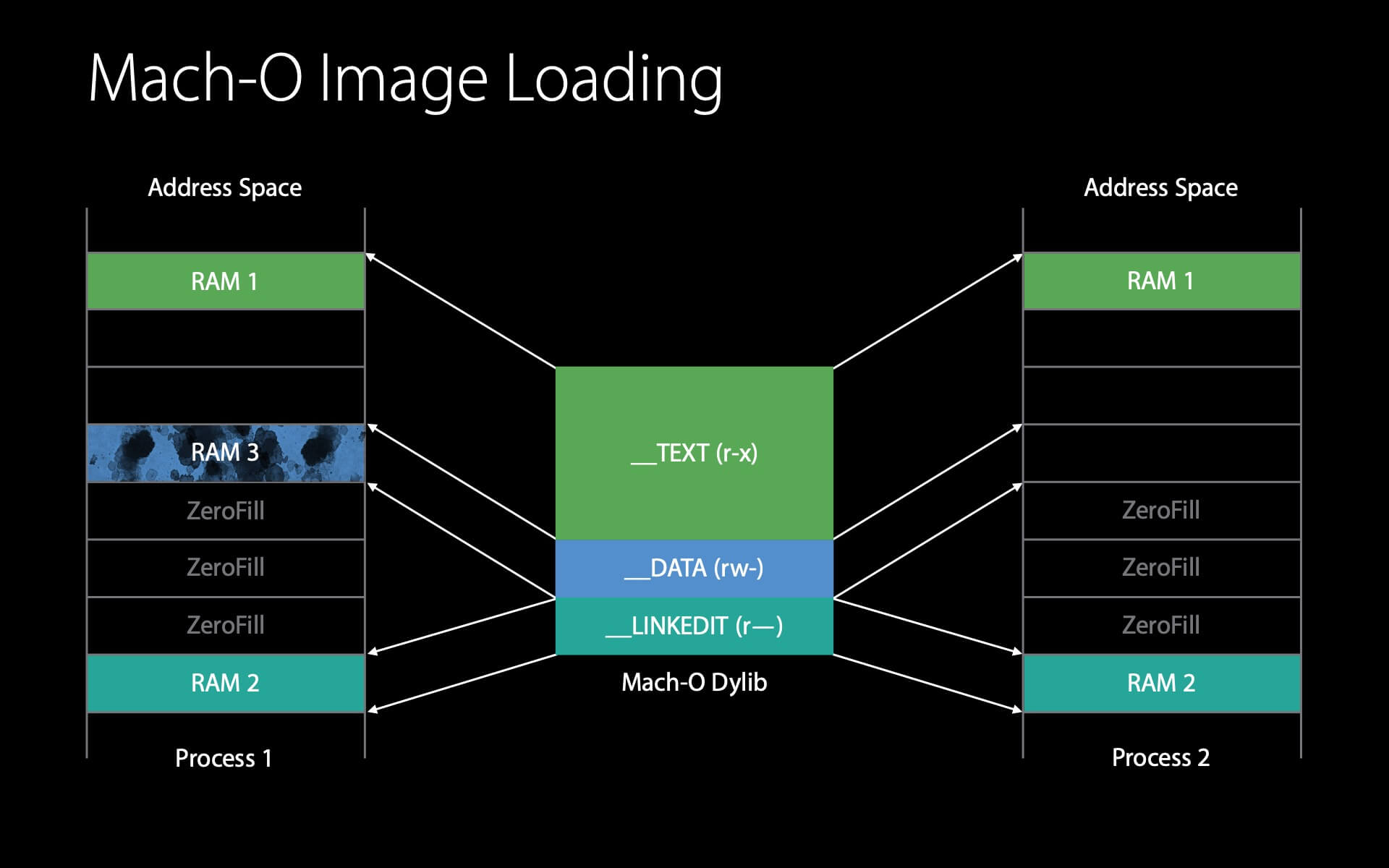
同样,__LINKEDIT 也在内存中,可直接复用。
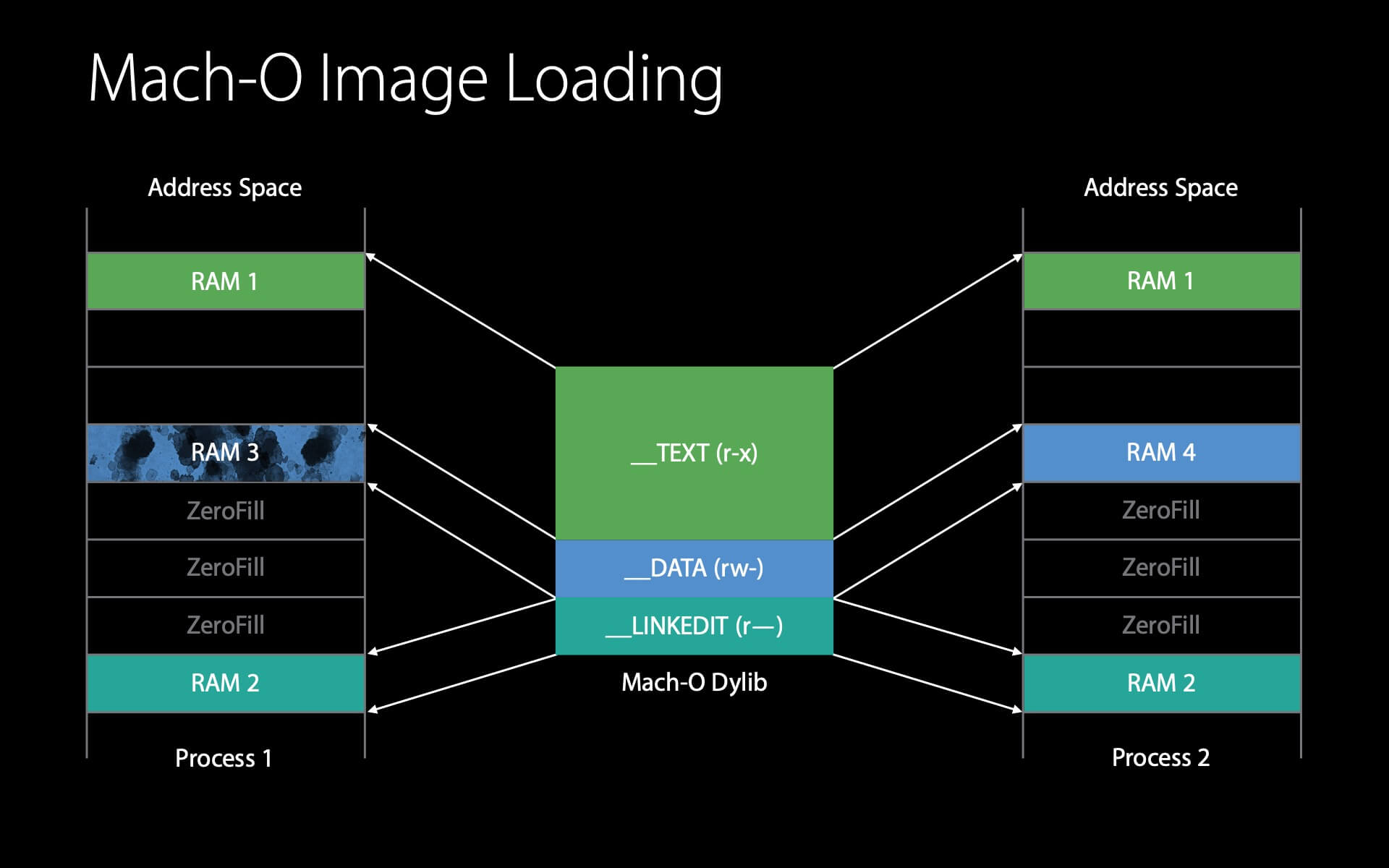
接下来是 __DATA 。内核会先查看这个 __DATA 页的 clean page 是否还在物理内存中,如果还在就可以直接复用,如果没有就需要从磁盘中重新读取。
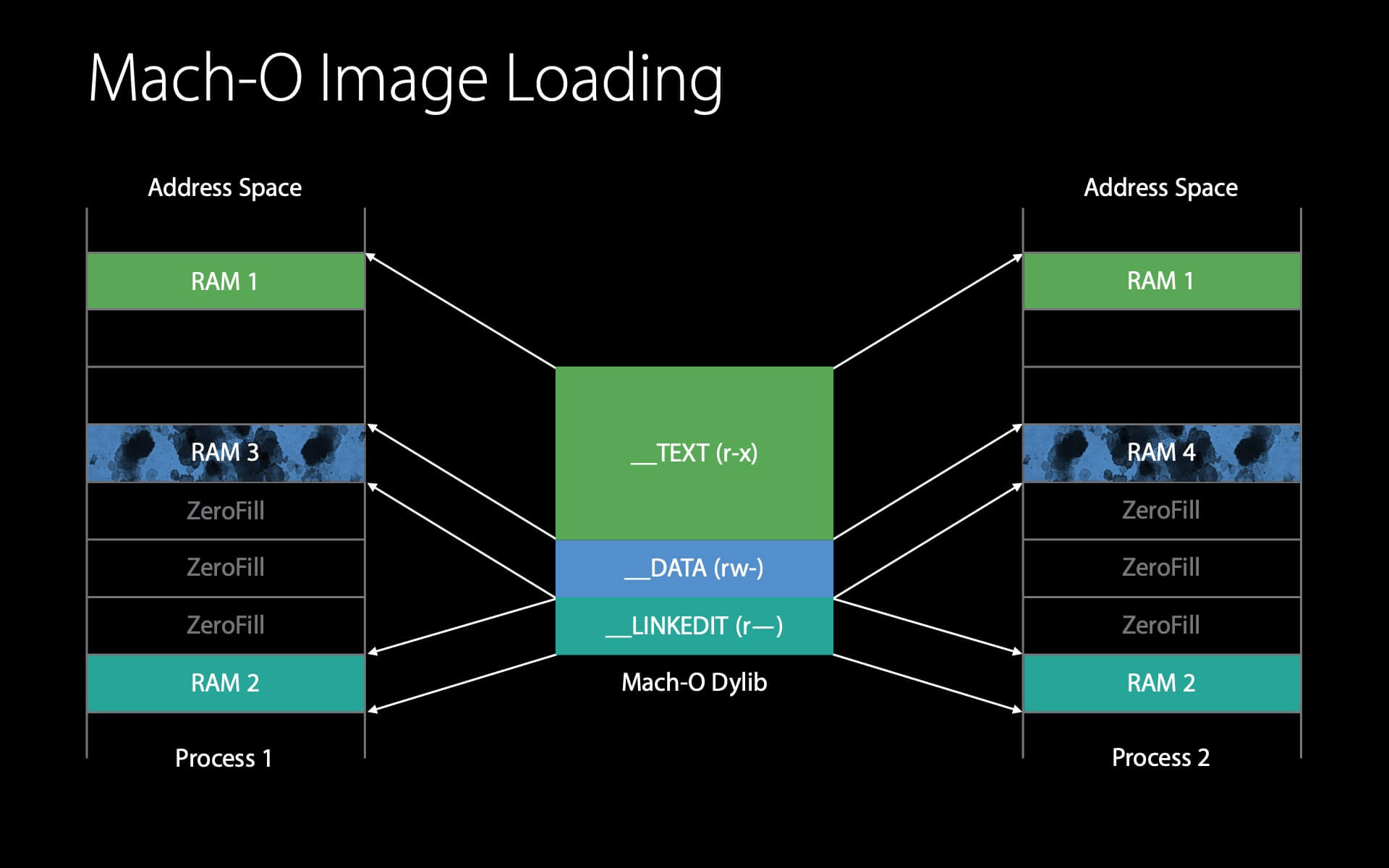
同样地,dyld 对这个 __DATA 页执行 Fix-ups 时会触发写时复制,并产生 1 个 dirty page 。
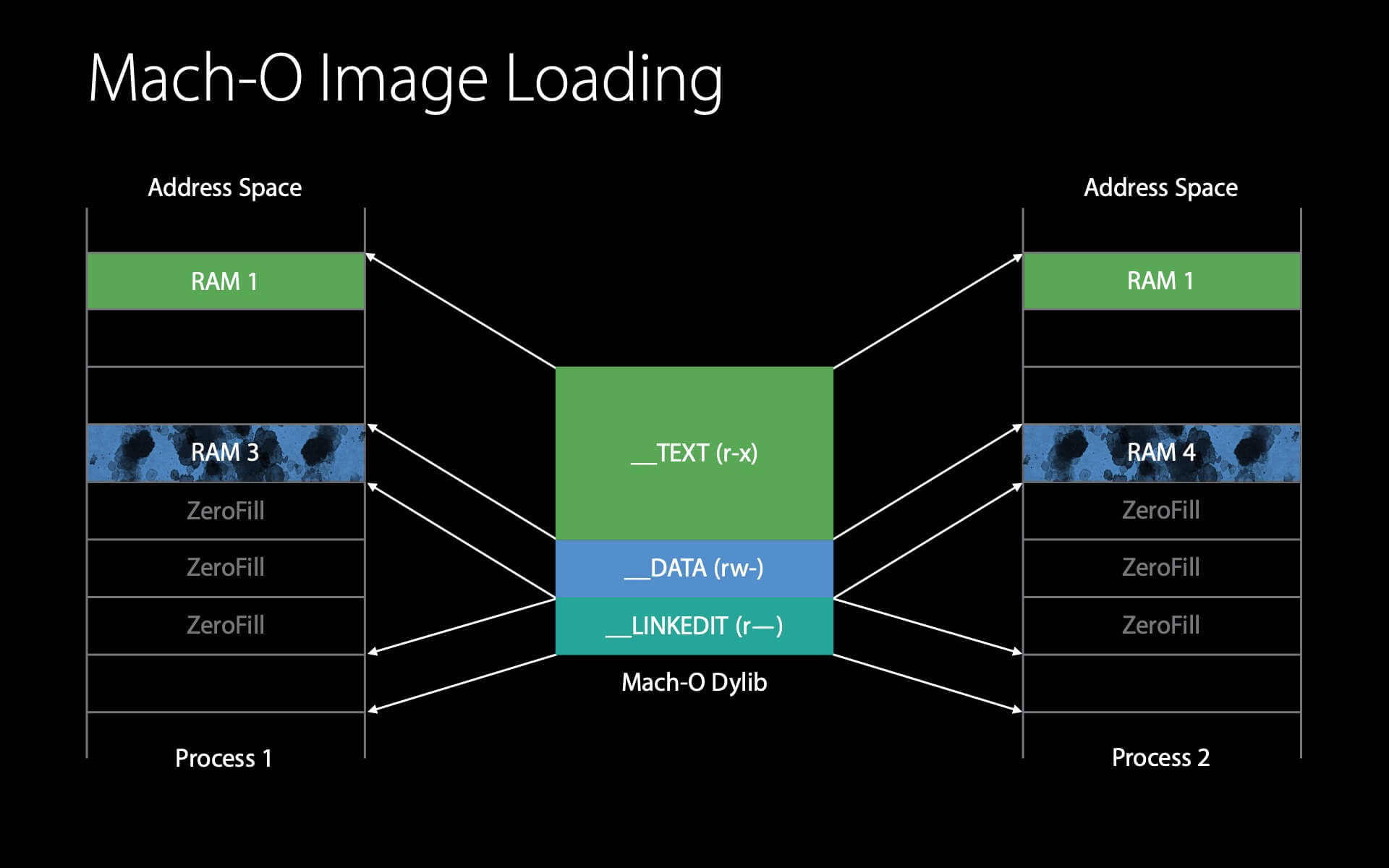
由于只有在 dyld 执行上述操作的时候才需要用到 __LINKEDIT ,因此 dyld 会在完成这些操作后告知内核它已不再需要 __LINKEDIT ,内核可以在其他程序需要内存的时候将 __LINKEDIT 占用的内存回收。
第二个进程加载 dylib 的小结:
这两个进程共享了同一个 dylib ,如果不共享且全部加载的话,会产生 16 个 dirty page ,但使用上述的操作方式,只产生了 2 个 dirty page 和 1 个共享的 clean page 。(小编注:演讲者应该是漏掉了 __DATA 的 clean page ,所以应该是 2 个共享的 clean page )
安全性
1. 地址空间布局随机化
地址空间布局随机化 (Address Space Layout Randomization, ASLR),指 Mach-O 文件会被加载到随机的地址上。
2. 代码签名
代码签名 (Code Signing) 是以页为单位的,Mach-O 文件的每一页都要被哈希,哈希值会在页被载入的时候验证。
内核的工作
1. 把 App 映射到进程中
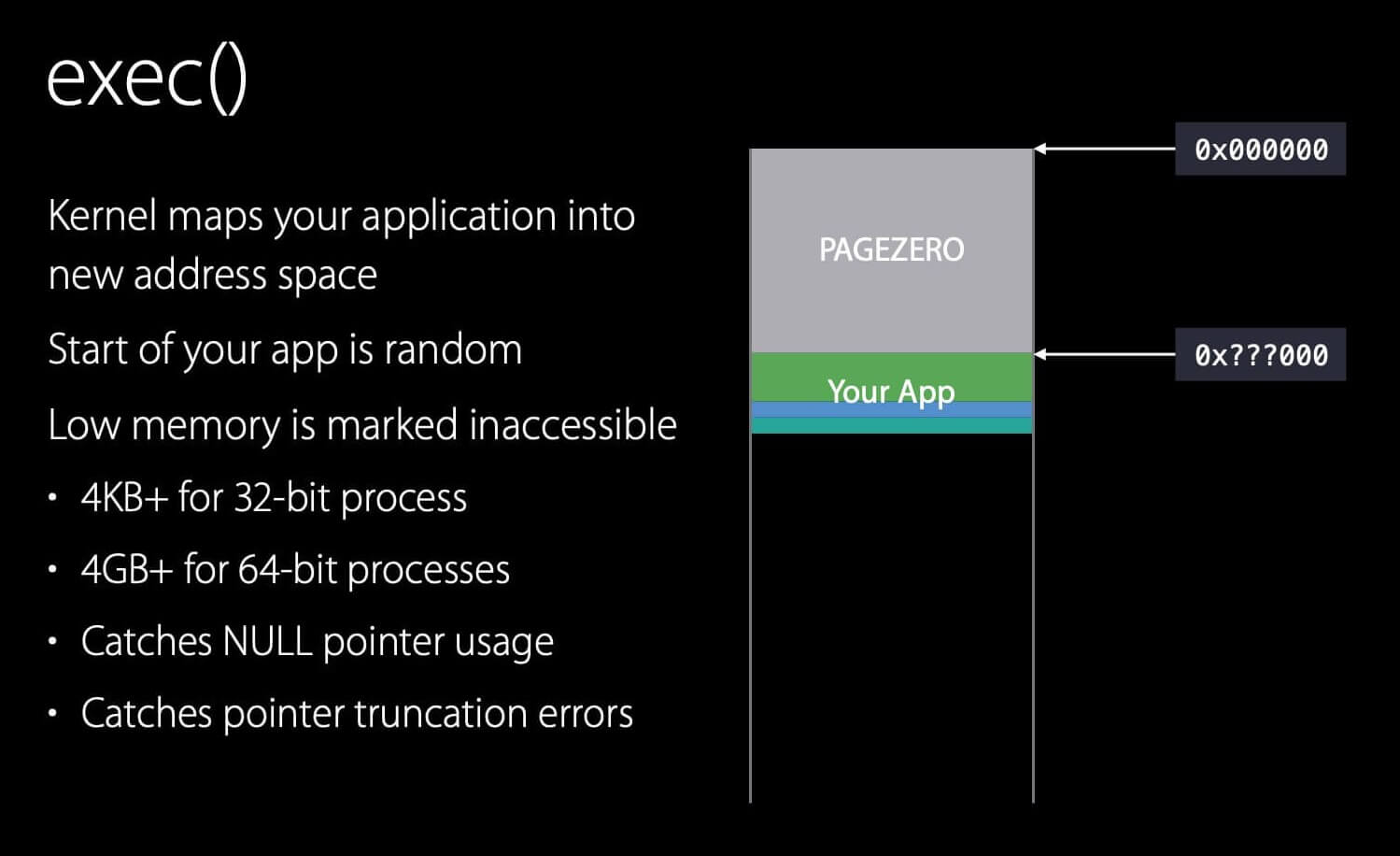
exec() 是一个系统调用 (system call) 。在陷入内核空间后,告诉内核想用这个新程序替换某个进程,内核就会删除该进程的整个地址空间,并映射用户指定的可执行文件到这个进程。
由于使用了 ASLR,dyld 会把 App 映射到一个(虚拟内存的)随机地址,然后把从 0 到这个随机地址的区域标识为不可访问 (inaccessible) ,也就是不可读、不可写、不可执行。这块区域的大小在不同平台上不一样:
- 在 32 位的系统上至少是 4KB ;
- 在 64 位的系统上至少是 4GB 。
它捕获 NULL 指针引用,以及指针截断错误 (pointer truncation error) 。
在 Unix 最初的二、三十年里,启动进程比较轻松,因为需要做的就是映射一个程序,把 PC 设置给这个程序,然后开始运行这个程序。
直到后来,动态库被发明了。
2. 把 dyld 载入进程中
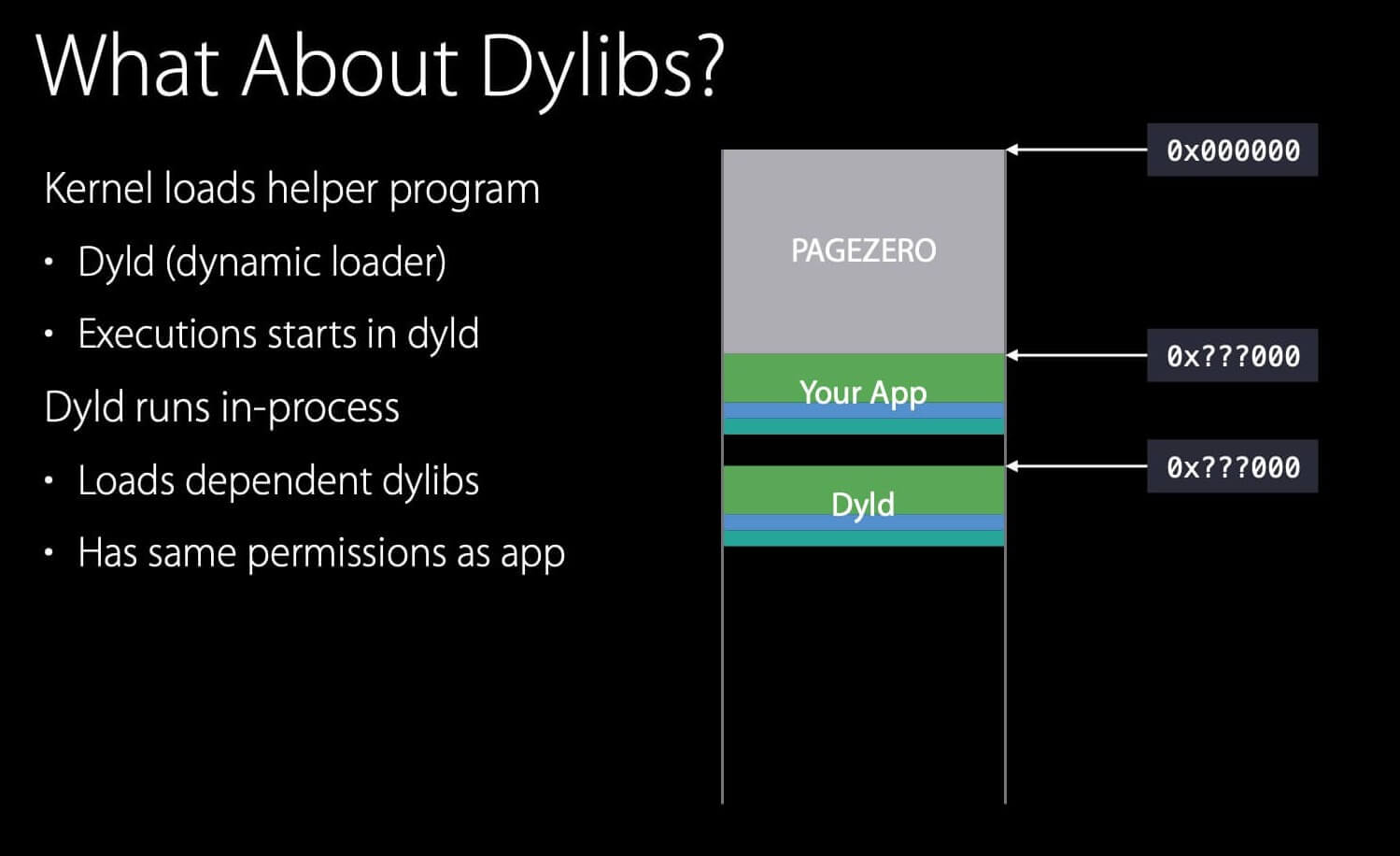
请注意,这里介绍的是
dyld 2。
dyld 2会被全部加载到进程中;而dyld 3被拆成了 3 个主要部分,且大部分模块不会被加载到应用的进程中,而是以守护进程 (daemon) 的形式存在,只有负责加载启动闭包 (launch closure) 的模块会被加载到应用的进程中。
那么谁负责加载 dylib 呢?
他们很快意识到,动态库的加载很快就变得非常复杂,而系统内核的开发者不希望让内核来做这些工作,所以就创建了一个辅助程序。在 Apple 的平台中,这个辅助程序被称为 dyld ,在其他 Unix 上被称作 LD.SO 。
因此,当内核把 App 映射到进程后,内核会把另一个叫 dyld 的 Mach-O 映射到这个进程的另一个随机地址中。然后,将 PC 设置给 dyld ,让 dyld 来完成这个进程的启动。
dyld 的执行步骤
请注意,这是
dyld 2的执行步骤。

1. 递归地加载所有依赖的 dylib

首先,内核已经把 App 加载到进程的虚拟内存中,dyld 会读取 App 的 Mach-O Header 中的 dylib 依赖列表,然后 dyld 再去查找每一个 dylib 。
每当找到一个 dylib ,dyld 会将其打开并查看文件的开头部分,以确定它是一个 Mach-O 文件,验证它、查找它的代码签名、然后将代码签名注册到内核中。
接着,就能对 dylib 的每个 segment 调用 mmap() 方法了。

App 依赖的 dylib 可能依赖了 A.dylib 和 B.dylib ,而它们可能又依赖了其他 dylib ,因此 dyld 会递归地执行这项任务,直到所有依赖的 dylib 都加载完成。
平均而言,Apple 系统上的 App 需要加载 1~400 个 dylib ,所以要加载的 dylib 非常多。幸运的是,它们大部分是系统的 dylib ,Apple 对它们做了大量优化,在构建/升级系统时,会预计算和预缓存大量工作,以加快 dylib 的加载速度。因此系统的 dylib 加载非常快。
2. Fix-ups

位置无关代码
现在 App 依赖的 dylib 都加载了,但是它们还处于互相独立的状态,接下来需要把他们绑定在一起。这个过程就叫 fix-ups 。
由于存在代码签名,因此不能改变指令。
问题:如果不能改变 dylib 的调用指令,那么一个 dylib 如何调用到另一个 dylib 呢?
其实这里又添加了一个间接层(indirection) ,被称作位置无关代码 (position independent code) 。
位置无关代码是指可在主存储器中任意位置正确地运行,而不受其绝对地址影响的一种机器码。PIC 广泛使用于共享库,使得同一个库中的代码能够被加载到不同进程的地址空间中。(来源:维基百科)
具体的做法是在 __DATA 段创建了一个指针,这个指针指向需要被调用的方法,所以 dyld 要做的是修正这个指针和数据。
Rebase & Bind

Fix-ups 有两类:rebase 和 bind 。
- Rebase: 修正指向当前
Mach-O文件内的指针; - Bind: 修正指向当前
Mach-O文件外的指针。
如果你好奇的话,有一个名为 dyldinfo 的命令,它有一些可选项参数。你可以在任何 Mach-O 文件上运行它,你会看到 dyld 必须为该 Mach-O 文件做的所有修改:
1
xcrun dyldinfo -rebase -bind -lazy_bind myapp.app/myapp

从图中可看到有 3 类信息:
- rebase information
- bind information
- lazy binding information
2.1 Rebase

由于使用了 ASLR 技术,Mach-O 文件会被加载到一个随机地址,因此所有的内部指针 (interior pointer) 都需要加上偏移量。
这些指针存在哪呢?这些指针被编码在 __LINKEDIT 段里面。(具体点?)
在做 rebase 的时候,会在所有的 __DATA 页中的触发缺页(因为应用的 Mach-O 文件对应的页还未加载到物理内存),并且由于需要写入数据,还会触发写时复制。
这些 IO 导致 rebase 很耗时。但由于 dyld 是按顺序执行的 rebase ,从内核的角度来看,缺页也是按顺序发生的,因此内核会提前读取后面的页,这使 IO 成本有所降低。